GPT2 Finetuning
Fine-tuning GPT-2 for dictionary-based language generation (Fall 2021)
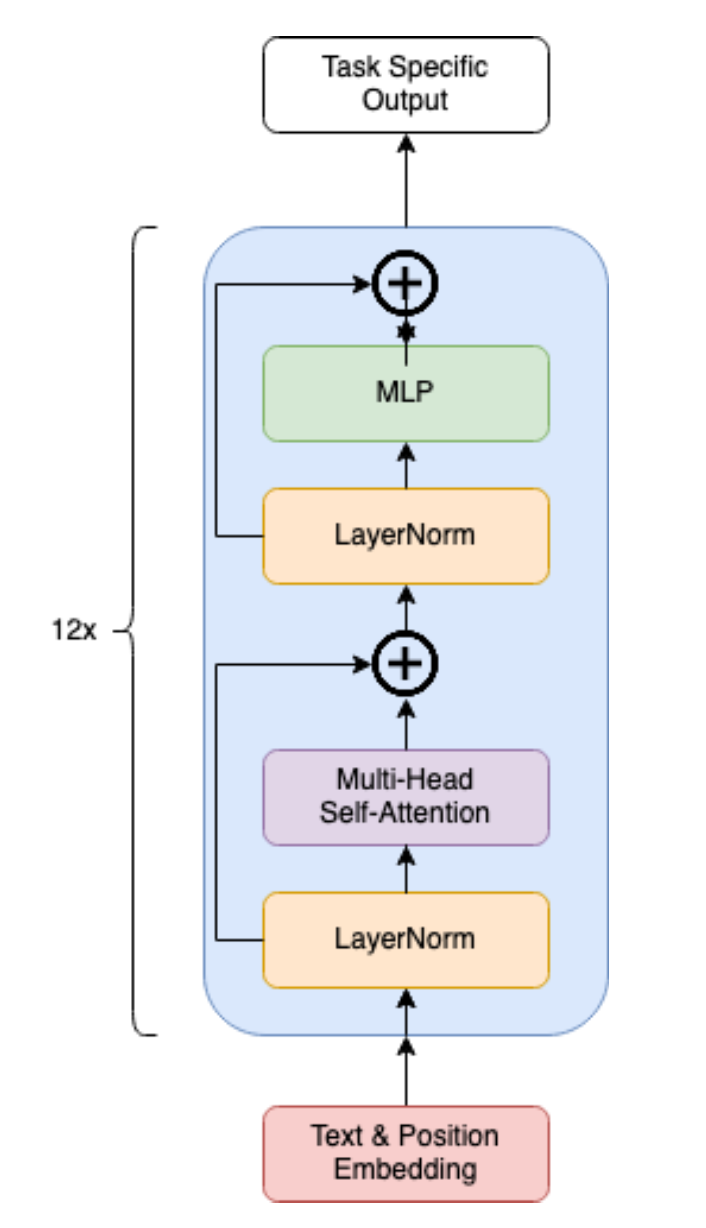
Overview
This project explores the fine-tuning of the GPT-2 model using Wiktionary data to enhance its ability to generate dictionary-style content. The goal is to adapt GPT-2 to model the relationship between words, definitions, and example usages effectively.
Introduction to GPT-2
GPT-2 is a unidirectional, causal language model pre-trained on a diverse dataset obtained from the internet. The core architecture of GPT-2 is based on the Transformer model, which employs self-attention mechanisms to process text sequences.
Key Components
Input Representation:
- The input sequence is tokenized into sub-word pieces using Byte-Pair Encoding (BPE)
- Positional embeddings are added to token embeddings to encode the position of each token
Mathematically: \(h_0 = \text{Dropout}(U W_e + W_p)\)
where \(W_e\) is the token embedding matrix, \(W_p\) is the positional embedding matrix, and \(U\) is the one-hot encoded sequence.
Transformer Blocks:
- Each Transformer block consists of multi-head self-attention followed by a position-wise feed-forward network
- Layer normalization and residual connections stabilize training dynamics
Self-Attention Mechanism:
The self-attention operation is defined as:
\[\text{Attention}(Q, K, V) = \text{Softmax}\left(\frac{Q K^T}{\sqrt{d}}\right) V\]
where \(Q\), \(K\), and \(V\) are the query, key, and value matrices, and \(d\) is the dimensionality of the key vectors.
Model Tuning and Evaluation
Dataset Preparation
- Dataset split into training, validation, and test sets
- Two versions created: Forward (word → definition) and Reverse (definition → word)
Tuning Procedure
- GPT-2 initialized with pre-trained weights
- Fine-tuned using AdamW optimizer
- Regular validation to prevent overfitting
Cosine Similarity for Evaluation
Used to evaluate similarity between generated and actual embeddings:
\[\text{cosine similarity} = \frac{\vec{x} \cdot \vec{y}}{\|\vec{x}\|_2 \|\vec{y}\|_2}\]
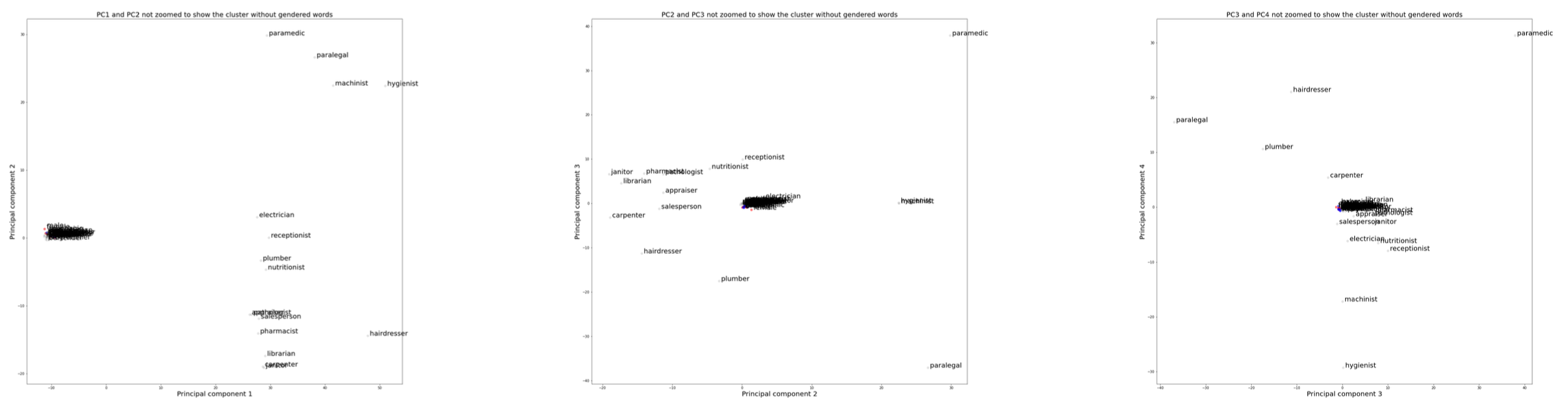
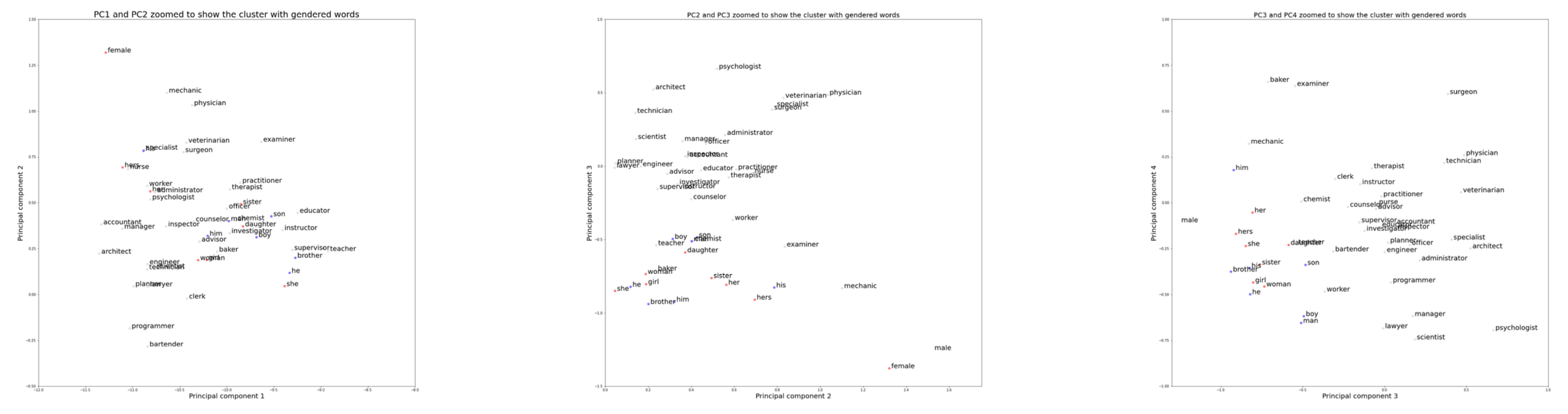
Findings
- The fine-tuned GPT-2 model demonstrated effective generation of definitions and example usages
- Cosine similarity evaluation showed generated embeddings closely matched actual embeddings
- Analysis revealed quantifiable bias patterns in the dataset
Conclusion
This project successfully fine-tuned GPT-2 for dictionary-based language generation. The Transformer architecture's self-attention mechanisms effectively captured complex relationships between words, definitions, and usages.